Client
FCDO, via Faculty AI
When the machine isn't sure, it should say so — and hand the hard call to a human expert.
Intelligence analysts work constantly with multilingual content — voice messages, documents, chat threads. AI translation is fast, but on ambiguous material it can be confidently wrong, and that risk is unacceptable here. The challenge was to design a workflow that combined AI translation with human expertise while cutting the manual coordination between analysts and linguists.
Through stakeholder discussions and workflow analysis, one thing became clear: the existing process was fragmented and ran on manual interactions. An analyst received content, contacted a linguist, waited, chased — review happened over email and side channels, with no shared view of status or history.
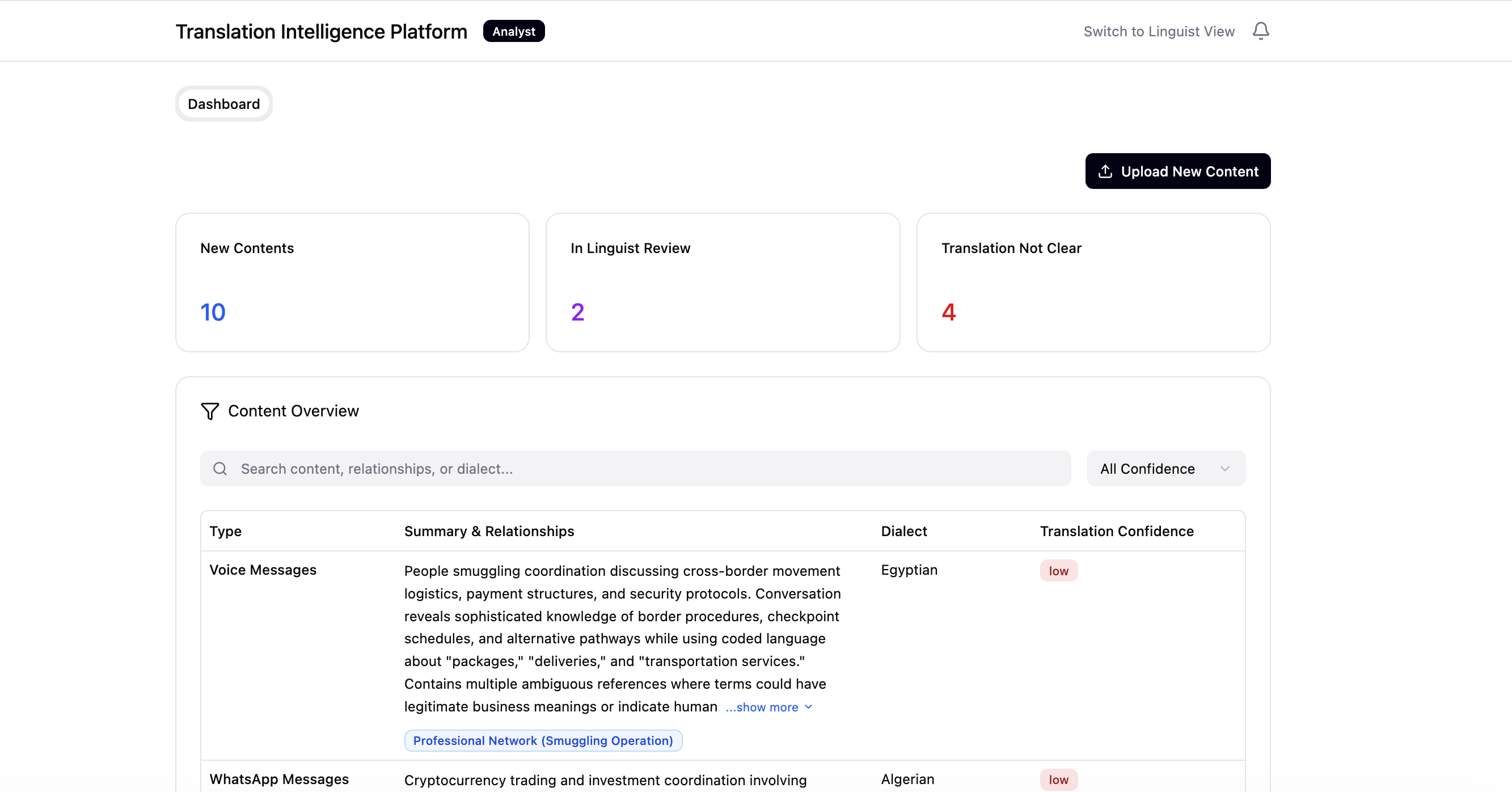
Analysts and linguists both review large volumes of content, so the dashboard leads with confidence tags — a fast way to spot translation risk and prioritise where review effort should go. High-confidence items move on; uncertain ones get flagged for a closer look.
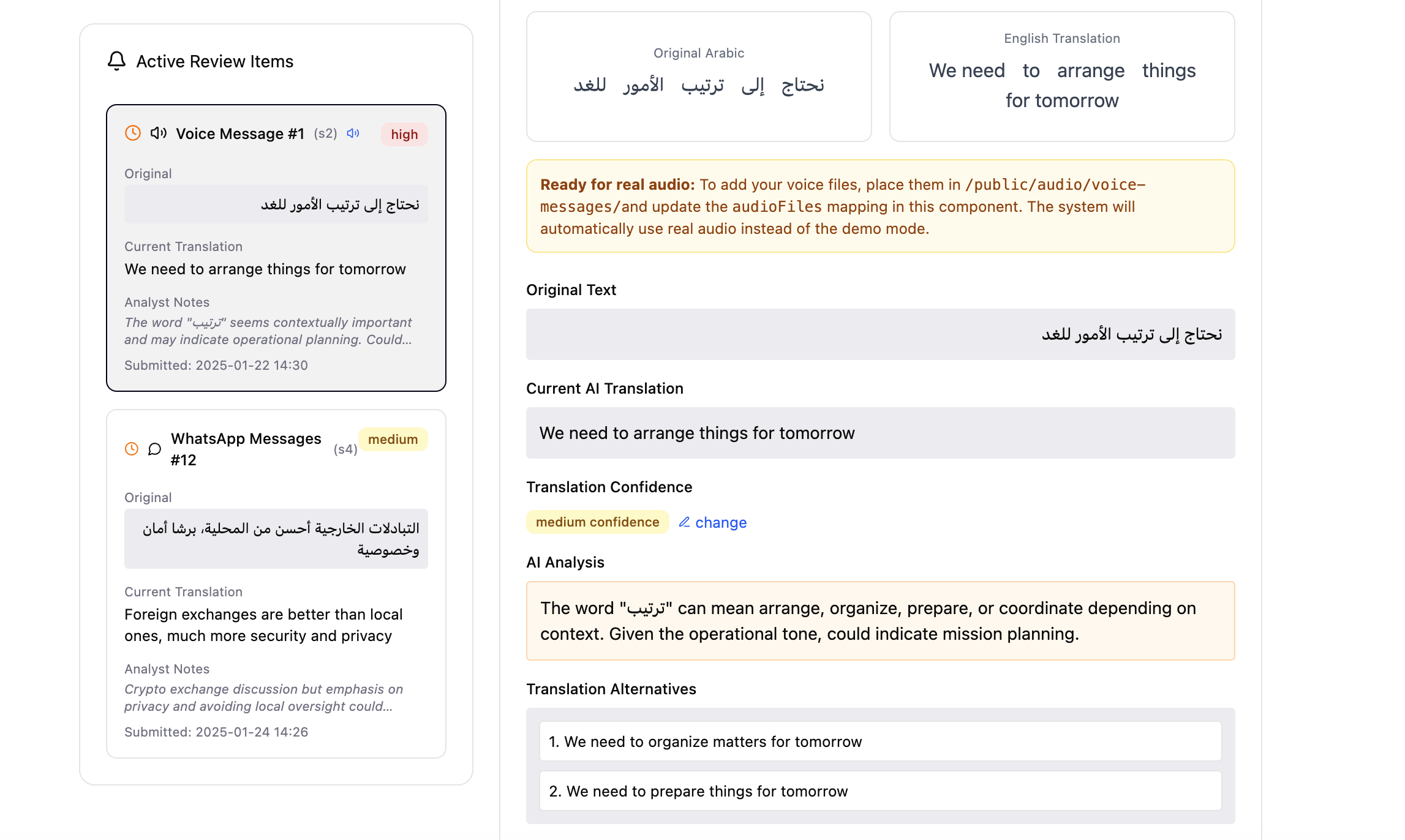
The core view puts everything a person needs to judge a translation in one place: the original, the AI translation, a confidence score, and the alternative interpretations the model considered. Uncertainty is shown, not smoothed over — so the reader can weigh it instead of trusting it blindly.
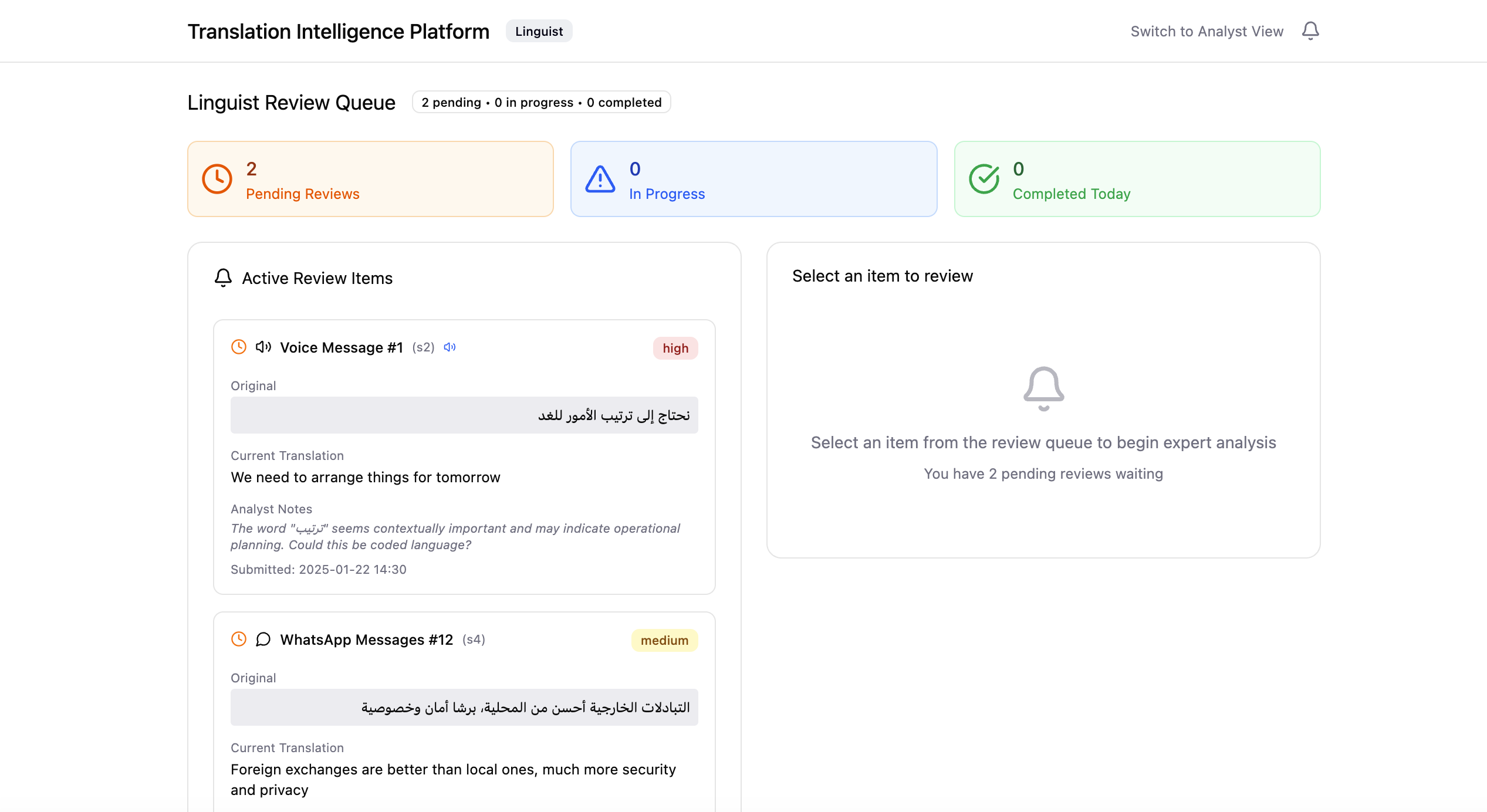
When an item is escalated, the linguist receives the original content, the AI translation, supporting context, and the exact phrases flagged for review. Many sources start as voice messages, where meaning rides on tone, emphasis and dialect — so linguists can play the original audio to validate both the transcription and the translation, not just the text.
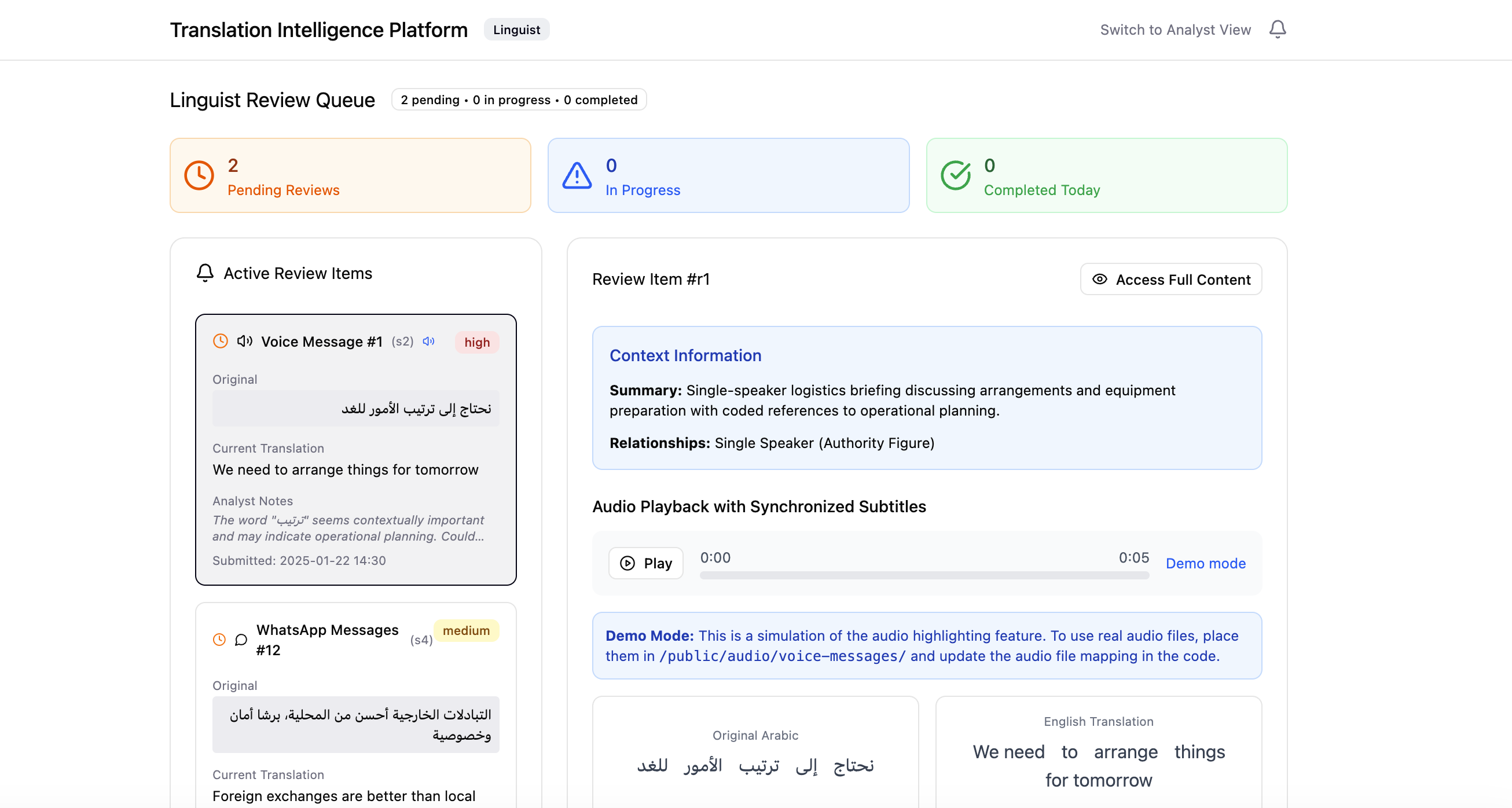
The platform replaces external back-and-forth with a shared workspace. Analysts and linguists see the same context, translation history and review status; once a linguist validates or edits a translation, the update flows back to the analyst automatically. No chasing, no lost threads.
The goal was never to replace human expertise. It was to make uncertainty visible — so the right cases reach the right experts.
The platform turned a fragmented review process into a structured, AI-assisted workflow. By pairing automated translation with expert validation, analysts processed content more efficiently while keeping confidence in the final interpretation. Most importantly, uncertainty became something the system shows — through confidence scores, alternative readings, and expert checkpoints — rather than something hidden behind a single, plausible answer.